
What colour was soldiers’ hair? Find out as we test our aggregation workflows
As we process our first large batch of data (thank you for the great progress made!) we’re interested in evaluating the accuracy of the work, and testing our workflows for aggregating multiple transcriptions on the same person into one. We began by looking at data for which we have verified entries—the name and the serial number.
Now we’re moving onto looking at how we aggregate text that takes on categorical values. A good rule of thumb in data processing is to start by looking at simple things first. In this case, simple is a question that doesn’t have a lot of possible answers. Hair color is an interesting one, and perhaps the results will be of interest. What color hair did New Zealand soldiers have?!
We were again encouraged by the apparent accuracy of the data. Of 3,216 transcriptions of hair color just 15 were not a hair color. Interestingly they were a religious profession which is beside it on the form. We can probably find the hair color in the entry for religion for these men. Transposition of entries from a known place is a problem, but a workable one. Of course, we should emphasize that an error rate of < 0.5% is really good.
 .
.
The example here also shows another funny issue. A couple of people transcribed this as “light possum”, and we can see why! Context suggests that it is “light brown”, and the majority of transcribers recorded it that way. But since we use “flaxen” for blonde, why not use “possum” for grey hair.
To the data! We find that New Zealanders were a dark haired people, with 80% of the soldiers being described as having “brown,” “black,” or “dark” hair. The “fair” including flaxen were a small minority.
| Hair colo(u)r | Frequency | Percent | Cum. Pct. |
| Brown | 414 | 57.50 | 57.50 |
| Black | 97 | 13.47 | 70.97 |
| Fair | 80 | 11.11 | 82.08 |
| Dark | 72 | 10.00 | 92.08 |
| Other | 22 | 3.06 | 95.14 |
| Red or auburn | 21 | 2.92 | 98.06 |
| Grey | 14 | 1.94 | 100.00 |
Working through this data was a useful trial for our aggregation of more complicated fields. We hope you found it interesting, and look forward to sharing more results with you as we continue our research. Thanks for all your hard work, and lets keep transcribing!
Evan Roberts for the Measuring the ANZACs Research Team (@evanrobertsnz).
Citizen science produces highly accurate transcriptions
We reported last week that we were analyzing the 545,000 fields transcribed from our first year of collaborating with our citizen army to tell the stories of and measure the ANZACs. Among the first things we’re looking at is this question: how accurate are citizen transcriptions. If you’re reading this blog post you’re already among the most engaged volunteers, and so you will be thinking “I take a great deal of care with my transcriptions!” However by having our project open to the world we trade off the benefit of openness for the cost of having some less experienced volunteers who may not read the instructions, or take as much care.
So our question is to measure the measurers: how accurate are they, are you?! We need to show you’re doing a job that’s as good as we could achieve with methods traditionally accepted in the academic world for transcribing this form of material, such as employing undergraduate or graduate students.
We have an amazing opportunity to measure the accuracy of transcription in Measuring the ANZACs because our index to the records includes three variables or fields: first name, surname, and serial number that we see in the data as well and that are being transcribed. So we have a “gold standard” we can compare to. In a lot of citizen science projects the research team have to hand validate a sample of their data (we’ll do a bit of that too).
We measure “similarity” between your transcriptions and the gold standard with a metric called a Jaro-Winkler score that measures the similarity of the “string” (a string is a sequence of letters or numbers). 1 represents complete accuracy, and 0 total inaccuracy.
But to make the scores more concrete consider that Charles and Cjarles have a similarity of 0.91; Gerry Reid and Henry Reid have a similarity of 0.8, and B and Benjamin have a similarity of 0.74. We can still make a lot of use of transcriptions that score as low as 0.7. Note in particular that “B” is an initial and this may just reflect that the paper had “B” instead of “Benjamin”. The transcription is accurate, but the original person writing it down should have put the full name.
Here’s what we found and presented at last week’s meetings of the Social Science History Association: Citizen scientists are creating highly accurate transcriptions on complex forms with messy handwriting. We have a little work to do to compare this to our previous data collection by graduate students, but on first impressions this is of a very high standard.
Transcription in citizen science is relatively new, and it is important to show that it produces acceptably accurate data. We think it has, and we look forward to now proceeding with our substantive analyses with a high degree of confidence in what we’re analyzing. As we continue with our validation of the data we’ll keep you informed. Now, lets get back to Measuring the ANZACs! Transcribe!
| Given name | Surname | Serial number | |
| Mean similarity score to truth (1 = absolute accuracy) | 0.98 | 0.98 | 0.98 |
| Proportion absolutely accurate | 0.87 | 0.84 | 0.89 |
| Proportion with similarity score > 0.9 | 0.95 | 0.95 | 0.95 |
| Proportion with similarity score > 0.8 | 0.97 | 0.98 | 0.98 |
| Proportion with > 3 words in string (more likely problematic transcriptions) | 0.0029 | 0.003 | 0.003 |
Audacious and achievable: Progress towards our goals.
We got a batch of data out from the system recently, with more than half a million transcriptions of questions and answers.One of the automatically recorded pieces of data when you transcribe is the time and date.
Here is the raw data. We had a great opening week, and then in late 2015 we had some website problems. You can see how that affected our numbers, probably along with it being the holidays. What are the two huge jumps in January and February? Those are the days immediately following our interviews on TV One and TV Three. If we were on TV every night think how quickly we’d be done. Many hands do make light work!
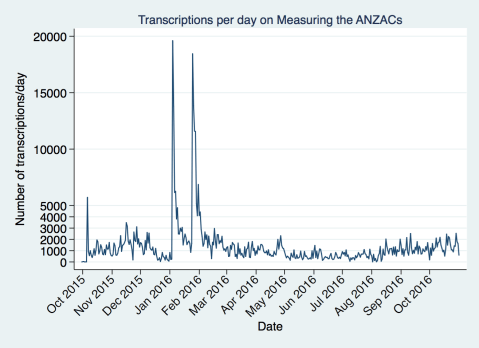 As you can see from this graph there are some day-to-day fluctuations that make it harder to pick out the trend. It looks like the fluctuations are weekly, reflecting when people have more or less time (or faster internet at work?).
As you can see from this graph there are some day-to-day fluctuations that make it harder to pick out the trend. It looks like the fluctuations are weekly, reflecting when people have more or less time (or faster internet at work?).
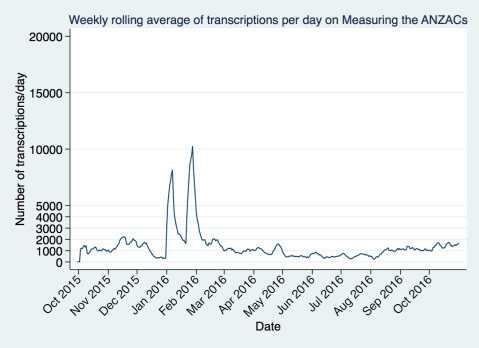
There are some formal statistical tests for the “periodicity” of data, but for simplicity lets just look at the average over a week. We take the rolling average which allows us to get away from worrying about the audience for our project which is in multiple timezones. In effect our weekends are nearly three days because the New Zealand weekend starts when it’s still Friday in the United States (we know our community comes largely from the UK, US, and New Zealand).
Here’s what that looks like. We got a bit of a bump from the news coverage early in the year, and then things drifted down.
Lets focus then on the more normal part of the year to see what’s happening over time. We got a bit of a bump from some presentations and publicity in April/May 2016, and things slowed down a bit after that. We’re really gratified to see that since our presentations in Wellington in July 2016 there’s been a sustained growth over the last couple of months. 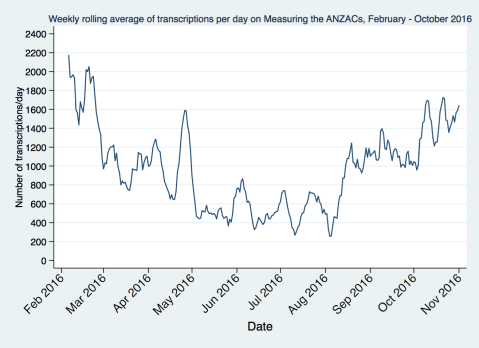
Is this enough to build a memorial and research database by the end of the centenary of World War I? Not yet! Every day we’re now completing the equivalent of about 2-3 files, depending on how many lines there are on the statement of services and History Sheets. By completing we mean that every field has been done three times.
How does this compare to other Zooniverse projects? Very well indeed. We’re not as popular as Galaxy Zoo or Snapshot Serengeti in classifications per day, but we’re around where Penguin Watch is, which is great. But our challenge is that each image (a page in a file) contains so much information. On each image we’re trying to get 5-30 pieces of information, whereas other projects have a smaller number of tasks per image. It’s just the nature of the material. So we need to keep going, and we need you, our force of transcribers to help us recruit more people. If you think there’s an analogy to the war and getting men to the front, you’re right. We need volunteers (and we need conscripts).
The goal is both audacious and achievable. Audacious because a complete transcription of the main pages of 140,541 files is a big task. Achievable because there are more than 3 million adults in New Zealand. If every high school student and their family adopted two soldiers and marked and transcribed their file we’d be done. If every one with an ancestor who served marked and transcribed one file we’d be done. Help us do that. Reach out now to people you know and share the goal with them. Thank you for a great foundational year, let’s keep going further and faster!
